Applied Ai In A Data Centric World
How many times have we heard sentences such as “Data is the new oil” or “Data is food for AI”? Even though there is some truth to these catchphrases (after all, we data scientists/AI scientists do spend most of our time on the data), the vast majority of academic AI papers still revolve around new approaches that improve x% on famous dataset benchmarks such as ImageNet. Even in the industry, most data scientists often get their data as a given constraint for the problem they need to solve, and not as a variable they can optimize to better solve their task at hand.

The idea to prioritize data over algorithms is not new. Actually, most leading AI companies (for example Tesla) are designing their AI workflows specifically to optimize data acquisition and tagging, However, this idea has been brilliantly reintroduced and explained by Andrew Ng in March 2021, and this is where (as far as I know) the term Data-centric AI (DCAI) was coined for the first time. Since Ng’s presentation, more and more people are joining forces to make AI more data-focused. Actually, a great hub was recently created to gather the most important resources and breakthroughs on this topic.
In this blog post, I do not want to explain the concepts behind DCAI in detail, since you can easily learn them from the links above. So before diving into the core ideas of this blog post, here is below the main idea of DCAI, so that you can continue reading even if you are not familiar with the field:


Even though the concept of DCAI is quite easy to grasp, I do think the implementation of DCAI in practice is far from obvious, so I want to discuss in this blog post the actual steps involved to make a successful DCAI project, and explain how it will change our job as AI/data scientists (non-related note: please forgive my lack of consistency in job titles, there’s unfortunately no standard across the industry). Basically, I want to answer the following questions:
-
Why now? What makes data-centric AI more relevant today?
-
Aren’t data acquisition and model optimization two orthogonal tasks that can be performed in parallel by different people?
-
Why and how does it completely change our work as Applied Scientists?
-
What are the most important steps of a successful DCAI workflow?
-
Where is the DCAI industry going in the future?
In particular, here are the main points I want to address in this post:
-
Iterating on the data is becoming much easier today, in particular thanks to the emergence of synthetic data (full disclosure: I work for a synthetic data provider called Datagen) and data labeling platforms.
-
State-of-the-art models on the other hand are becoming a commodity.
-
The DCAI methodology starts with engineering your TEST set (spoiler: I should have written test setS).
-
In a DCAI world, the most important task AI scientists will have to perform is debugging their algorithm to find the optimal data their network needs (good news: it’s much more exciting than traditional debugging!).
-
The future of DCAI will likely involve powerful AIs that would automatically debug neural networks, and derive from this debugging the kind of data that needs to be created.
Why is data-centric AI happening now?
You may have noticed that the idea of DCAI is overall quite simple, obvious and even not so new. This fact induces 2 important questions:
-
Why would the DCAI revolution happen now? After all, deep learning started to take off almost 10 years ago now, and it has always been clear that data was the core component there.
-
Aren’t data acquisition and model optimization two orthogonal tasks? In other words, maybe it makes sense that the AI scientists focus on the algorithm while someone else focuses on gathering more data?
The answer to the first question lies in the fact that up until now, data acquisition was a slow, complex, and expensive process, which involved a lot of operational challenges. In particular, there are 3 important operational (but not scientific!) challenges that need to be addressed when building a high-quality dataset:
-
Data diversity: you need to make sure your data is highly varied, has enough edge cases, but at the same time be careful to avoid biases in your dataset. For example, if all of your pictures come from a sunny country, your machine learning model may perform really badly on rainy days (side note: did you ever notice that most self-driving cars were all initially tested in sunny places?)
-
Labeling: this step is a difficult and approximate science: different conventions lead to different labels. Sometimes, having the exact labels is even an impossible task (for example it is impossible for humans to extract the exact 3D information from an image, since an image is by definition 2D).
-
Formatting: all data should be wrapped up in a format that contains all the information you need.
However, things have changed at many levels nowadays:
-
Creating state-of-the-art deep learning models has never been easier. Almost all the top AI papers now come out with open-source code, many python libraries such as huggingface, fast.ai, or pytorch lightning enable developers to train deep learning models with the latest architectures (for example, Transformers) and training tricks (e.g. one-cycle learning policy).
-
More and more companies are selling data (some datasets can even be downloaded and used for free). However, while this solution is faster, it can still be very expensive, and most importantly will rarely cover your edge cases.
-
The data labeling process has been considerably streamlined by products such as scale.com, Amazon Sagemaker, or Dataloop. Things like finding labelers to work on your data, creating labeling redundancy (to improve labeling consistency), and managing data are now much easier.
-
The rise of synthetic data (computer-generated data) is a complete game-changer for the world of AI (in particular computer vision). This type of data enables companies to acquire realistic data with perfect labels and perfect control, at a fraction of the time (and cost) it takes to acquire real data. It has also been proven (in particular by Datagen and Microsoft) that synthetic data can significantly reduce the amount of real data you need to train a model. In practice, synthetic data gives a real superpower to AI scientists: being able to create the data they need.
Therefore, the same way the Internet made it so simple for entrepreneurs to create companies and iterate on their projects, the commoditization of data acquisition enables AI practitioners to quickly create a baseline for their model, and iterate efficiently on the data until it is ready to be deployed.
Let’s now address the second question mentioned at the beginning of the paragraph:
Is acquiring data part of an AI scientist’s job? 
If you read the previous paragraph carefully, you probably already have the answer. A few years ago, acquiring data used to be an OPERATIONAL job, and had therefore no reason to be handled by an AI scientist (who would probably have done a very poor job anyway ^^).
However, the commoditization of data discussed above enables the AI scientist to fully engineer the data he or she uses to train a model. And as we will see, this engineering task is far from simple, and requires important research skills.
In other words, in most cases, I would say that YES, part of our job as AI scientists is to gather the data you need to train a model.
The 5 steps of a data-centric AI development
Ok, all this sounds very cool, but what does it mean in practice? If my job is not so much to train models anymore, what should I do then? How does this DCAI methodology get implemented in practice and what is our role in it as scientists?
(Rest assured, you will see that your scientific skills are critical to the success of a DCAI project!)
Step #1: Carefully engineer your test setS!!
This is something that few people talk about, but the implementation of data-centric AI should actually start with your TEST SET (or more precisely validation set as we’ll discuss later).
In principle, the test set (and metrics achieved on this test set) is the ground for many very impactful business decisions. In particular, the results of your algorithm on your test set will likely be the key element to decide whether or not it should be deployed to production. However, very often, data scientists create their test sets just by taking a random split of their training set. While this may be fine for a PoC, it will quickly show its limit if you want to build a robust algorithm that won’t fail every 2 days in production.
The first 2 things a data-centric AI scientist needs to build are:
-
A generic test set, which represents as closely as possible the probability distribution of cases you expect to get in production.
-
Several “unit test sets”, which consist in designing specific test sets that are meant to measure whether your algorithm is robust to specific cases (for example: can a car detect pedestrians in low-light conditions). This approach was in particular well explained by Tesla’s Head of AI Andrej Karpathy.
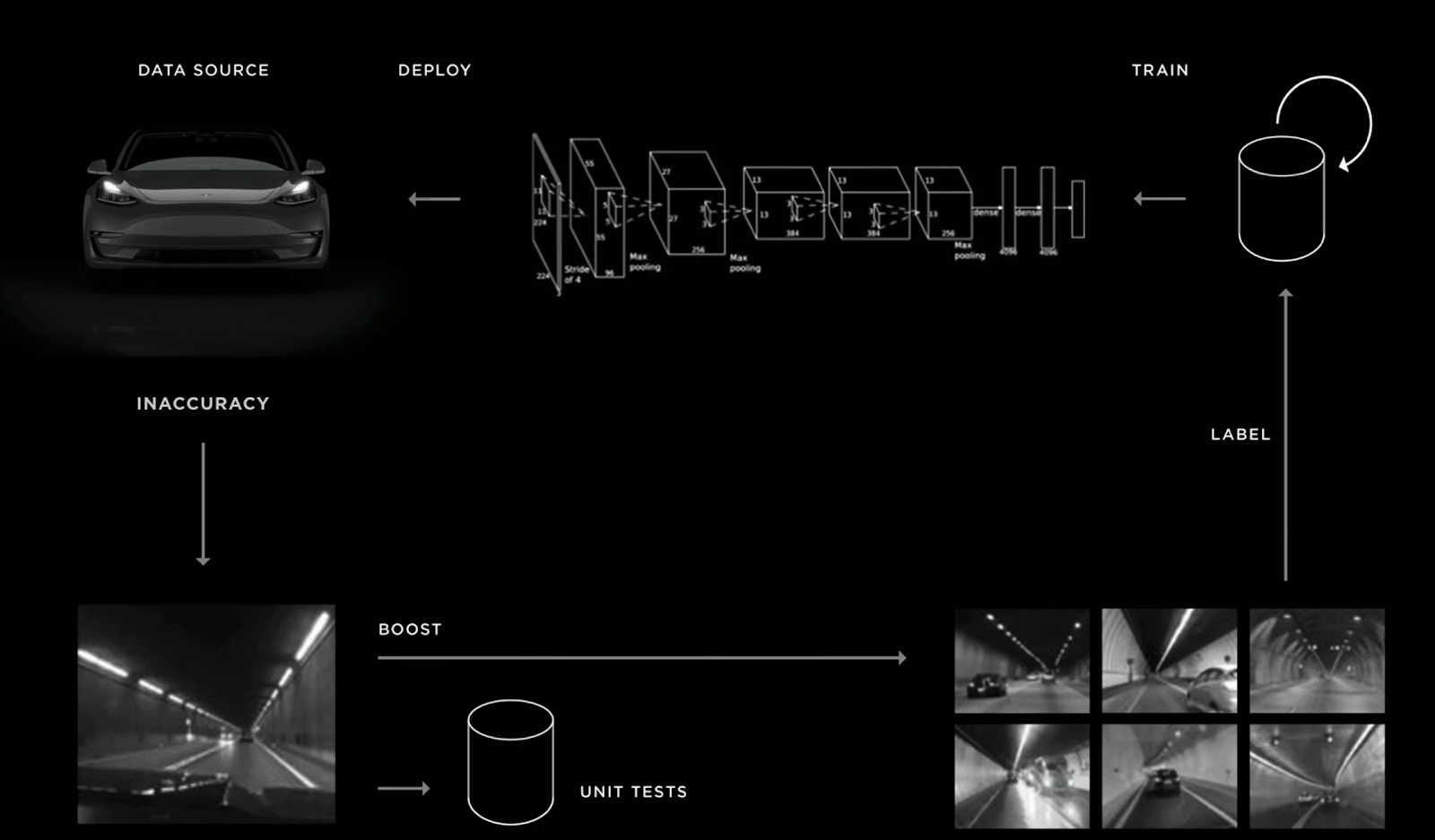
Source: slide from Andrej Karpathy’s (Tesla’s Director of AI) presentation at Tesla 2019 Autonomy Day
Step #2: Get your end-to-end data-centric pipeline running
Finish your test environment
Although building the test set is generally the most laborious step to building your evaluation environment, you cannot achieve much if you just have data. Ideally, your evaluation process should also include:
-
Proper metrics that describe the trade-offs you’ll need to make in production (for example, execution time vs accuracy). And yes, there ARE ALWAYS trade-offs.
-
Debug visualizations that show things that your metrics cannot quantify, if possible in a way that allows you to understand the problem more specifically. For example, if you build an image denoising algorithm, you should have a visualization of the inputs/outputs/ground truths side-by-side so that you can compare them and detect artifacts such as blur.
-
A one-push-button system (e.g. python script) to evaluate any given method according to all of the points described above.
As a side note, throughout my career, I’ve been struggling to find good tools to help me build test environments more quickly. While many MLOps solutions exist today (Weights & Biases, Tensorboard, etc…), they are usually very focused around Machine Learning (which imposes a constraint on the solution to your problem), and are often more about debugging your networks than evaluating a given solution. Today, I am more and more using a tool called QA-Board, an open-source software released by Samsung which provides a complete environment for a combined quantitative and qualitative evaluation environment. ~~
~~
Build your baseline
In order to finish your end-to-end data-centric pipeline, you also need a baseline, i.e. the quickest solution you can find to your problem that can be evaluated in your environment. I talked about this more in depth in my first post “Fall in love with the problem”, but it’s worth saying it again: your baseline SHOULD NOT take you a long time to build, and SHOULD NOT give good performances. The goal is to check that all the blocks of your pipeline are integrated, and to be able to “appreciate” the quality of the results you’ll get when you will use more complex solutions. Very often, you actually don’t even need a training set to build a baseline: you can either go for non-ML solutions, or leverage the ocean of open-source code available online.
Ok, now that you have your end-to-end pipeline running, it is time to improve on your baseline, and this is where things will spice up from an algorithmic perspective.
Step #3: Discover the data you really need
Thanks to the efforts you put in step 1 and 2, you may be able to get some initial insights on your baseline’s performances. For example, it may fail on specific unit tests, and this may give you a hint regarding the type of data you want to gather.
But more often than not, defining accurately the data you need is much harder than it looks, because the failure modes of your algorithm are in general unknown in advance, and your “unit test sets” are only wild guesses of the kind of data that could cause an algorithm to fail.
Surprisingly, I did not find a lot of academic papers answering the question “What are the 2-3 main characteristics in my data that cause my network to fail”. As far as I can see, there are 3 potential approaches there:
Deploy the algorithm in shadow mode

Even though your baseline is far from robust enough, it may be a good idea to put it in production in “shadow mode”, meaning that its predictions will not affect anything, but you’ll be able to gather a lot of data and monitor the kind of corner cases you’ll have to face. Here is a quick table of pros & cons for this method:
| Pros |
|
|---|---|
| Cons |
|
Data attributes inference
Whenever your test set is big (and it should be), it is often very hard to find interpretable characteristics of your data that correlate with your network’s failures. But if you enrich your unit test sets with metadata (such as number of people, location of objects, etc…), you’ll be able to leverage many classical data science techniques (KDE, clustering) across INTERPRETABLE dimensions of your data. For example, if you run an inference network on each of your test images to infer the gender of the subject for each image, you may suddenly realize that your algorithm performs much better on men than women, which is a directly actionable insight from a data perspective since you can add more women to fix this issue. In order to perform this enrichment, you can take advantage of all the off-the-shelf networks that exist today. For example, Google’s Mediapipe project makes it very easy for anyone to extract information (3D face landmarks, body pose, etc…) about images, with relatively high robustness and accuracy.
Another possibility is to use synthetic data as a test set. Since synthetic data are built by an algorithm, every metadata you wish to have about this data is theoretically accessible. For more details about this approach, I highly recommend reading Datagen’s Neurips paper.
Unstructured failure modes discovery
Unfortunately, in many cases, you won’t know beforehand the characteristics of your data that are causing a network to fail. Ideally, we would like to have a toolbox that analyzes the model’s performances, and gives us actionable insights on how to improve them.
While the academic literature is relatively scarce on this topic, here are 2 interesting works I came across recently:
-
Stylex: very recent and interesting paper by Google that shows how to automatically discover and visualize the main data characteristics that affect a classifier. In other words, their method will help you identify and visualize exactly the attributes that cause a dog vs cat classifier to classify an image as dog or cat.

Explaining a Cat vs. Dog Classifier: StylEx provides the top-K discovered disentangled attributes which explain the classification. Moving each knob manipulates only the corresponding attribute in the image, keeping other attributes of the subject fixed. Source: Google’s blog post
-
Virtual Outlier Synthesis: another amazing and recent paper. They basically found a way to generate images that are out-of-distribution, i.e. corner cases that the network hasn’t seen a lot during training, and is therefore struggling on. Although this paper doesn’t really bring an explanation as to WHY these outliers are failing, the fact that it can generate new failure case candidates by itself is pretty amazing.
As part of my work at Datagen, I’ve also developed such a method to detect neural networks failure modes in an unstructured way. More precisely, I built a Variational Auto-Encoder that can transform an input failure case into the most similar image that would make the network succeed. When trained and tested on the facial landmarks detection task (on the 300W dataset), we observed for example that the VAE was removing glasses from people, and transformed babies into grown-up faces, hinting that the network has more difficulties dealing with babies and people with glasses.




(As you may know, one of the famous problems with VAEs is that they create blurry pictures, as can be seen above. While this may be an issue in many cases, it is not in our “debugging” case, because these images are meant to be interpretable, not beautiful).
Step #4: Gather the new data and adapt your training pipeline
Once you’ve identified the type of data you need, you need to gather more of this data. This is typically where things may get harder: if you need real data, you may need to write a long list of precise requirements, and wait for 6 months until you get the new dataset back. This is exactly why I believe synthetic data is going to be a revolution. You can now use platforms like Datagen to create data with the exact characteristics of your failure cases, and a lot of variance on everything else.
However, keep in mind that your training procedure may need to be adapted if you have a new dataset. In particular, if you use synthetic data, both our team and Microsoft observed that 2 important changes need to happen in your training procedure:
-
More data augmentation is needed, because synthetic data is often “too clean”, and therefore does not represent well enough the real world.
-
Label adaptation: unless the labeling conventions of the synthetic data completely aligns with the ones you use in your test sets, you will need to find a way to adapt the output of your network so that it fits the ground truth of your test set, and not the one of your synthetic data. We have found that the easiest and most effective way is to pretrain your network with synthetic data, and then fine-tune it on real data.
Step #5: Scale it until you make it!
Once you have your data-centric process installed, you will need to repeat it as fast as possible, i.e. perform the following steps:
-
Analyze the failures as described in step 2 → Conclude about the dataset to add
-
Generate one or several new datasets based on these insights.
-
For each new dataset found:
-
Retrain the network with this new dataset (+the previous ones to avoid the catastrophic forgetting issue)
-
If this new dataset improved the performances in your unit tests:
-
Keep it for future iterations.
-
Go back to step 1 with your freshly trained network
-
-
If it did not:
-
Drop this new dataset
-
return to step 1 with the previous network
-
-
Important note: For the sake of simplicity, I’ve mostly talked about test sets for now, but needless to say that as soon as you start iterating over this test set, and start to make decisions based on your test sets’ results, your final algorithm has a strong risk of overfitting. This is why all this closed loop optimization process should happen with the validation set, and not really the test set per se.
Long-term: AI-powered data-centric AI
At the end of the day, the whole concept of data-centric AI is to engineer the data you need to optimize the performances of your machine learning model in real-life. However, as we saw, figuring out the optimal data you need to solve a task, and how to adapt your training procedure to this data, are very hard algorithmic tasks. Therefore, I believe that the future of data-centric AI is to build a complete closed-loop system (some kind of next-gen AutoML) that not only optimizes your model’s hyperparameters, but also the data it gets fed with.
If you think about this for a second, this idea is actually very comparable to how a child learns. Of course, a child’s brain learns very quickly and efficiently from any data it comes across. However, the data he or she receives is not random at all: it is carefully selected by people who care for the child more than anyone else in the world, and are also (hopefully) themselves very smart: his parents.
However, in order to get there, a lot of very interesting problems need to be addressed:
-
On the AI side: as we’ve seen, discovering the failure modes of your network, how to adapt your training procedure to new data, and how to optimally generate data based on those failure modes are still research questions, and I personally haven’t found a lot of papers dealing with it.
-
On the MLOps side: no matter how smart your algorithms are, you will always need a lot of trials and errors to figure out the best training data and hyper parameters. This means that you will require automated systems that can run as many experiments as possible in parallel, while optimizing all of your hardware resources. Some of these experiments will be related to data gathering, some others related to neural network training, and they will need to communicate and be orchestrated in a very smart way. I actually expect the demand in MLOps tools for DCAI to grow very quickly in the coming years. I personally would love to have such tools.
As you can see, data-centric AI is one of the most exciting areas to work on, as it is both THE most impactful way to perform AI, and it is actually itself full of fascinating AI challenges! If working on those challenges gets you excited, you should definitely talk to us!